Introduction:
Publicly accessible multimodal large language models (LLMs) have recently gained attention as potential tools for flexible medical image interpretation. Their performance on 12-lead ECGs, however, remains insufficiently characterized. In this study, we evaluate the diagnostic performance of the latest multimodal LLMs in interpreting clinical ECG images across key electrophysiological categories.
Methods:
Eight publicly accessible multimodal LLMs (ChatGPT-5, ChatGPT-4, Gemini 2.5 Pro, Copilot, Grok-4, Perplexity, Claude Sonnet-4, Claude Opus-4.1) were tested using 70 anonymized ECG images from our cardiology ward patients. A standardized prompt required nine categorical outputs: rhythm, first-degree AV block, intraventricular conduction delay (and subtype), QTc prolongation, premature atrial and ventricular contractions, ischemic ST-segment deviation, and axis deviation. Expert consensus from two cardiologists served as reference. Accuracy metrics and Cohen’s κ were calculated; response times were recorded.
Results:
Overall accuracy varied substantially across models (68.1–78.3%; p<.001). The latest OpenAI model, ChatGPT-5, reached the highest accuracy but had the longest response latency (median 276 s) (Figure 1). Rhythm classification showed moderate accuracy (72.9–82.9%), yet sensitivity for atrial fibrillation was consistently low (≤22%). First-degree AV block and QTc prolongation were rarely detected (sensitivities 0–33% and 0–45%). Intraventricular conduction delay was identified with up to 70% accuracy, whereas subtype differentiation remained limited (≤44%). All models demonstrated very low sensitivity for ischemic ST-segment deviations (<25%). Agreement with expert interpretation was low; Cohen’s kappa values (κ≤.37) reflected only poor to, at best, fair concordance beyond chance level (Figure 2).
Conclusions:
Current generalist multimodal LLMs show moderate overall accuracy but fail to reliably detect clinically relevant ECG abnormalities. Their diagnostic reliability is insufficient for clinical deployment. Advancements will likely require domain-specific training, improved visual encoders, and hybrid architectures combining LLM reasoning with dedicated ECG algorithms.
Figure 1:
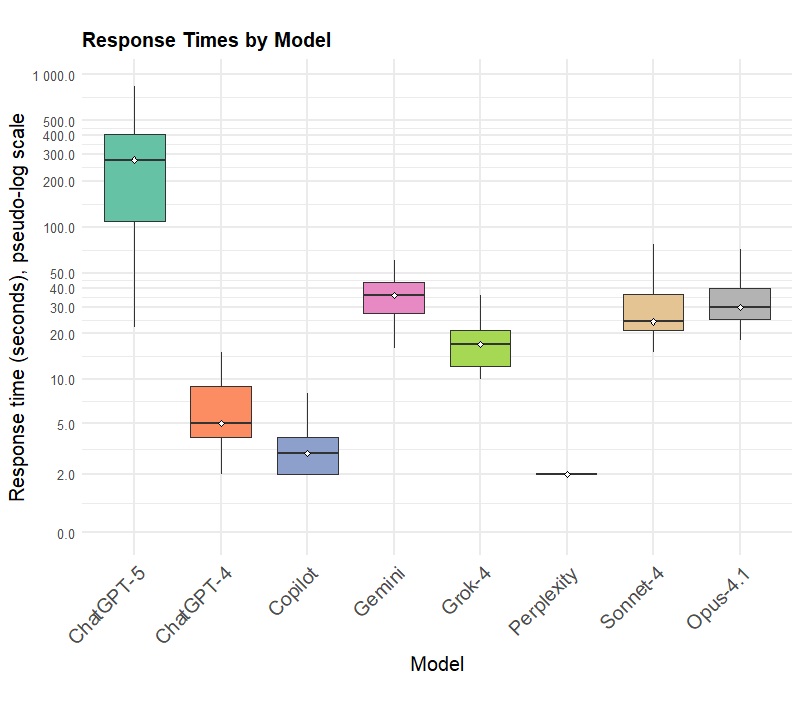
Figure 2: