Background Patients with chronic heart failure (CHF) have an increased risk for adverse outcomes. Risk prediction for adverse outcomes is of high relevance to tailor optimal medical guidance and therapy for the individual patient. Various scoring tools have been proposed to guide clinicians in assessing the risk for death and HF hospitalizations in CHF patients. However, these models often rely on parameters not routinely collected in daily clinical practice.
Objectives The Use Case Cardiology (UCC), part of the HiGHmed consortium within the Medical Informatics Initiative, aims to leverage large-scale clinical routine data of German hospitals for individualized risk prediction. This study aims to demonstrate the feasibility of utilizing clinical routine data from a single UCC university hospital to develop a risk prediction model for adverse outcomes in CHF patients.
Methods The analysis includes 1304 patients enrolled at Hannover Medical School between 2018-NOV-26 and 2024-NOV-18 with at least one follow-up. Clinical data encompasses medical history, medication, electrocardiogram (ECG) and laboratory results. The primary endpoint , death, was collected through follow-up every six months. The median follow-up time was 32.4 months. A baseline data set was created from the longitudinal data closest to study inclusion (+/- 30 days). Preprocessing involved excluding variables and patients with extensive missing data, while variables with less than 10% missing values were imputed using a simple imputation method . The subsequent final baseline data set comprises 1032 patients (33% female; mean age: 70 ± 14 years; 7% NYHA I, 45% NYHA II, 48% NYHA III/IV) and 77 variables. Within a repeated nested cross-validation process (repetitions = 5, k_outer = 5, k_inner = 3), a feature selection utilizing Cox regression, LASSO, ElasticNet and Variable Importance (VIP) via Random Survival Forest (RSF) was performed before statistical and machine learning models (Cox regression, LASSO or RSF) were developed. Models were evaluated using C-index as well as Area Under the Curve (AUC) and Brier score after 1 and 2 years, respectively.
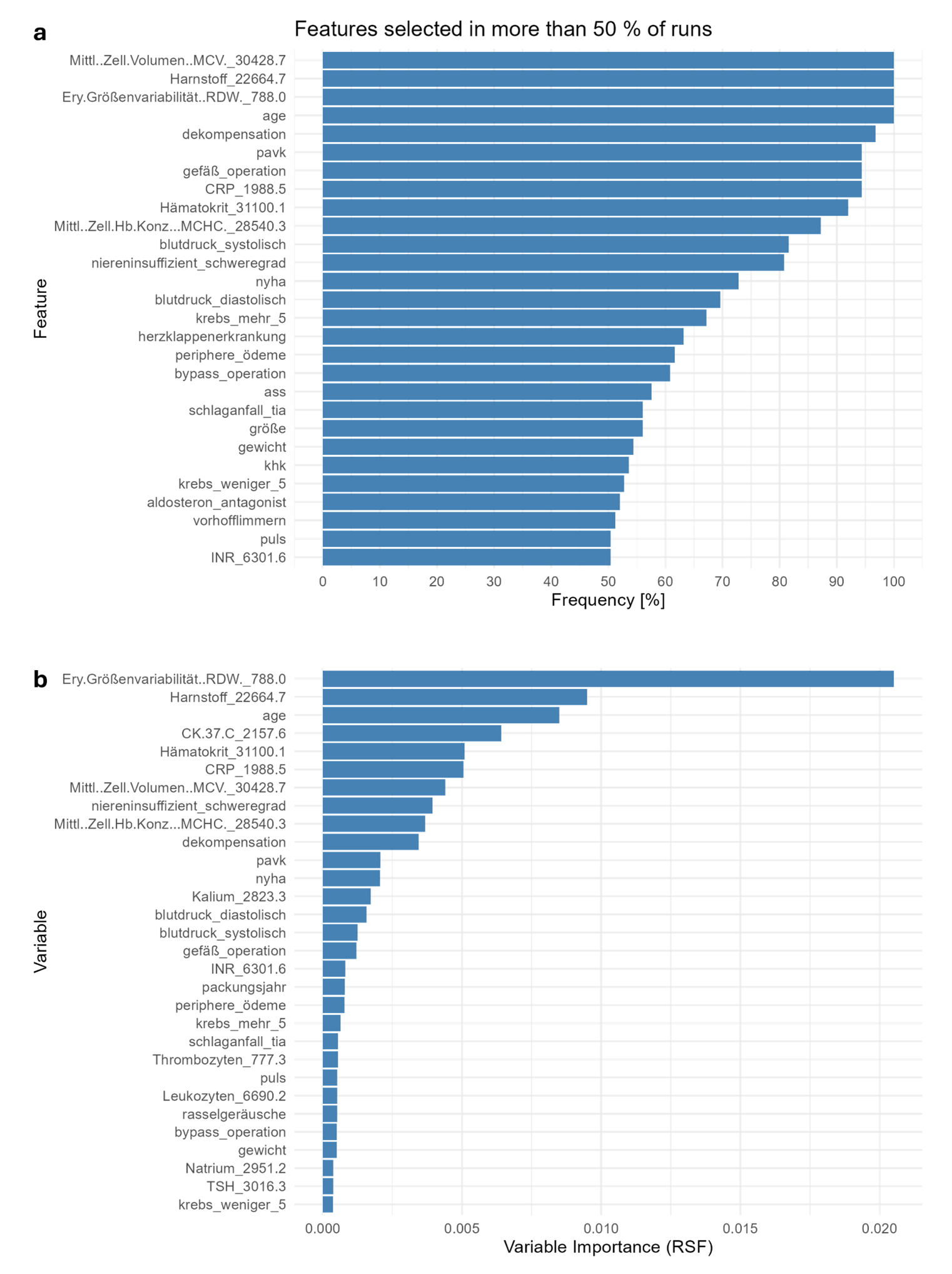
Results The primary endpoint death was reported in 166 patients (16.1 %). Figure 1 illustrates further stratification of the survival analysis, indicating a highly significant difference based on age and NYHA class (p<0.0001, respectively) while no significant difference was observed for gender (p=0.96). Figure 2 depicts that the best predictive performance was obtained using a combination of VIP-based feature selection (preselecting an average of 19.6 features) and a LASSO model, yielding mean AUCs of 0.82 and 0.81 after 1 and 2 years (Figure 2a-2b), respectively, a mean C-index of 0.80 (Figure 2c ), and mean Brier scores of 0.07 and 0.12 after 1 and 2 years, respectively. Mean corpuscular volume (MCV), urea, red cell distribution width (RDW) and age have been selected in 100% of feature runs (see Figure 3a). VIP identified RDW to be the single most important parameter for risk prediction, followed by urea, age and creatine kinase (Figure 3b).
Conclusion Large-scale clinical routine data provide a valuable foundation for developing robust risk prediction models in CHF patients. The comprehensive real-world nature of such data mitigates the issue of data incompleteness that often affects other risk scores in clinical practice.
Figure 1: Survival of the HiGHmed Cohort at Hannover Medical School
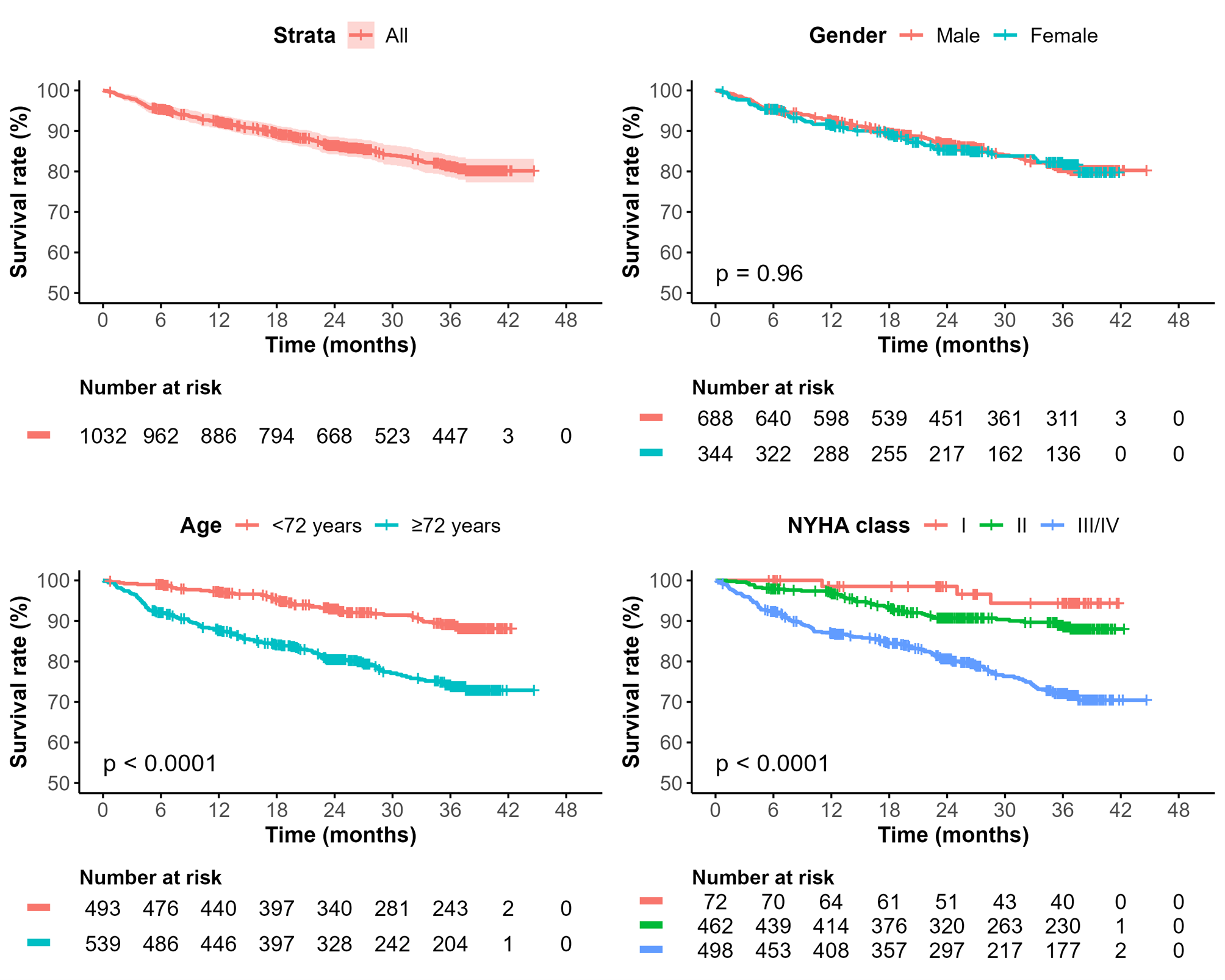
Figure 2: Comparison of Model Performance
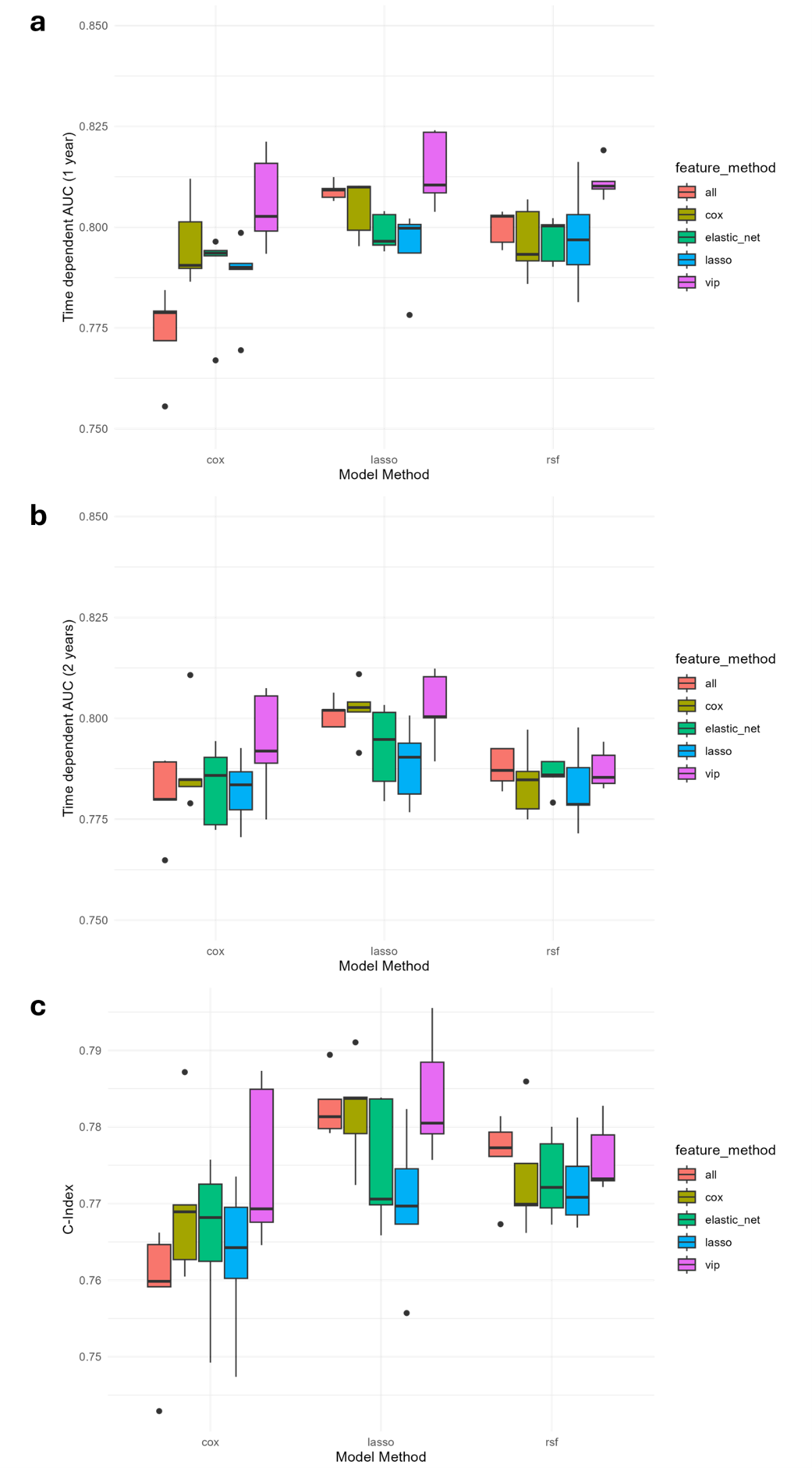
Figure 3: Feature Selection Frequency and Importance